Video
Video Introduction
This is a great (though long) introductory lecture into relational databases.
Flat Files
Flat File Databases
A flat file database consists of data stored within a plain text file. Records are stored one per line and each attribute of the record is separated by a delimiter – often in the form of a comma or tab.
A flat file is the simplest form of database and simplicity is its biggest advantage.
- The database has little overhead as the only metadata in the file are the delimiters
- The database can be read easily by human beings or by many different programs
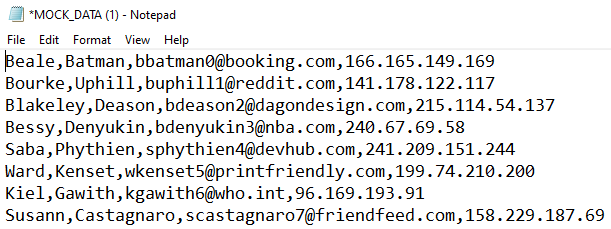
An example flat file database, generated automatically using Mockaroo.
Limitations of Flat Files
Limitations of file based systems
One of the quickest and easist ways to save data persistently (so that you don’t lose data when the computer is switched off or the program you are running closes) is to save the data to a text or csv file. The files are great if you are just ‘dumping’ the data (such as writing to an error log) or saving configuration settings, but when you start to handle large amounts of data or when you need to be able to edit or search the data you run into problems.
Limitations
- Text data must be read sequentially, which means that if you have thousands(or even millions) of items in the file it is going to take a long time to read the data.
- There is no in-built search function, so you have to search through data manually.
- You often cannot edit a single line, you have to rewrite the entire file.
- Filtering is slow and difficult – you have to import all the data into an 2 dimensional array and filter the data from there.
- Because there is no way of establishing relationships between the data entered, there is often large amounts of redundancy in the data (duplication)
- As the metadata is stored externally to the database data dependence occurs – where the integrity of the programs become dependent on the formatting of the data.
This means that file-based systems usually only the most appropriate solution for the simplest of situations and a relational database is more appropriate.
Relational Databases
Relational Database Model
Relational database work by splitting data about different entities (types of things) into separate relations (tables). Each relation only contains data about one entity and relationships (connections) are made between each of the relations through the use of primary and foreign keys.
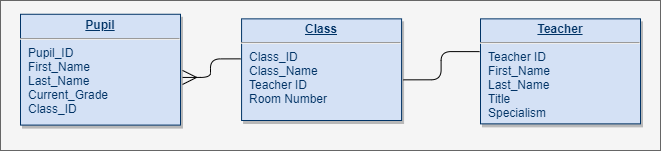
A simple design for the relations(tables) in a relational database.
Each table still only contains the actual data about the entity itself:
Pupil Table

Teacher Table
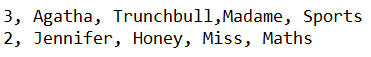
Class Table
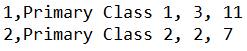
It’s import to note that the tables themselves do not contain any metadata detailing what data is stored in each column. This is stored in a separate part of the database known as the Data Dictionary.
By separating the data into separate tables there is less duplication, therefore less chance of corruption of data. However due to the relationship information stored in the data dictionary you can use a language called Structured Query Language (SQL) to perform powerful and complex queries, combining information from multiple tables.
Among other things SQL allows :
- Sorting of data
- Searching of data
- Filtering of data
- Combining data from multiple tables using join queries
RDMS
The creation, maintenance and querying of a relational database is controlled by a software system known as a Relational Database Management System.
Features of Relational Database Management Systems.
- Features of a DBMS:
- Allows the creation of database & tables
- Management of database and tables
- In-built security measures
- Developer console
- Query Builder
- Multiple views (e.g. forms & reports) and access levels