Data Mining
Data Mining

Data mining is the process of discovering patterns, correlations, and trends by sifting through large amounts of data stored in repositories, using various techniques from machine learning, statistics, and database systems.
It involves the extraction of hidden predictive information from large databases and is a powerful tool that can help companies focus on the most important information in their data warehouses.
Mining Steps
Data Mining Steps
1. Data Collection and Preparation
Gathering relevant data from various sources and preparing it for analysis. This step includes data cleaning, integration, and transformation.
2. Data Exploration and Understanding
Using descriptive statistics and visualization techniques to better understand the nature of the data, its quality, and the underlying patterns.
3 .Model Building and Validation
Applying appropriate algorithms to discover patterns and relationships within the data. T
3. Deployment and Interpretation of Results
Using the patterns and relationships found in the data to make decisions or predictions. The interpretation of these results should align with business objectives and needs.
Cluster Analysis
Cluster Analysis
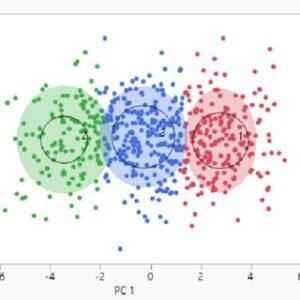
Image Source: Researchgate
This is a technique used to group sets of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups.
It’s widely used in statistical data analysis for various applications, such as pattern recognition, image analysis, and bioinformatics.
Clustering does not use pre-labeled classes; instead, it identifies similarities between data points and groups them accordingly.
Classifications Analysis
Classifications Analysis

This technique involves finding a model (or function) that describes and distinguishes data classes or concepts. The model is then used to predict the class of objects whose class label is unknown.
It’s based on training data consisting of a set of training examples. Classification is common in applications where you need to categorize data into predefined labels, such spam/not spam.
Associations Analysis
Associations Analysis

Association analysis is a rule-based method for discovering interesting relations between variables in large databases. It’s often used in market basket analysis to find relationships between items purchased together.
The classic example is the “beer and diapers” scenario, where supermarkets discovered through association rule mining that these two products were often bought together.
Sequential Analysis
Sequential Pattern Analysis
Sequential pattern mining is a topic in data mining concerned with finding statistically relevant patterns between data examples where the values are delivered in a sequence.
It’s used in a variety of contexts, such as analyzing customer purchase behavior, web page visits, scientific experiments, and natural disasters.
Forecasting
Forecasting
Forecasting involves using historical data as inputs to make informed estimates or predictions about future events. In the context of data mining, forecasting is often associated with time-series data analysis, used for predicting future trends based on past data.
Common applications include stock market analysis, weather forecasting, and sales forecasting.